Технический аудит сайта используется для того чтобы выявить его слабые места и исправить их. Для проведения такого рода анализа используют специальные программы и сервисы. Мы расскажем в этой статье как провести на сайте аудит с технической стороны, используя для этого специальную программу — Screaming Frog.

Настраиваем программу для последующей работы.
Можно, конечно, проводить анализ и со стандартно настроенной программой, но мы советуем внести в настройки некоторые изменения. Для начала в конфигурациях перейдите во вкладку advanced и поставьте отметки на пунктах respecrt noindex и respect canonical. Так вы сможете анализировать сайт таким, как он будет индексироваться.
Парсинг объёмных сайтов
Если на сайте, который вы собираетесь анализировать, довольно много страниц, по парсинг может длиться даже несколько дней. Зачастую ошибки в каждом разделе сайта носят одинаковый характер, потому глубину парсинга можно поставить на 4-5 уровне. Чтобы это сделать во вкладке Limits того же меню конфигураций выставляем показатель Limit Search Depth.
Также для объёмных сайтов лучше отключить функцию остановки парсинга в случае использования большого объёма памяти. Для этого во вкладке advanced надо убрать отметку напротив Pause On High Memory Usage.
Парсинг отдельных страниц
Для того чтобы провести анализ отдельных разделов или страниц сайта в меню конфигураций include задать шаблоны страниц и разделов. Таким же образом можно исключить из парсинга страницы и разделы.
Так вы не только ускорите процесс, но и уменьшите нагрузку на сайт.
Парсинг сайта, который находится в разработке
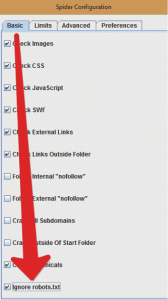
Ещё до запуска сайта и даже до выкатки его на основной домен надо проверить его и исправить ошибки. Для этого анализ сайта проводится когда он находится ещё на сервере разработчика. Тут вам понадобятся данные для аутентификации. Если у вас есть логин и пароль — входите и анализируете без проблем. Также, так как сайт на этой стадии закрыт для индексации, необходимо включить такую опцию, как ignore robots.txt. Иначе парсинг не начнётся, ведь программа работает с поддержкой этого файла.
Таким образом, вы сможете исправить некоторые ошибки ещё до завершения разработки. Но после открытия сайта для индексации и настройки инструкций robots.txt надо будет провести парсинг повторно.
Скорость проведения анализа сайта
Скорость парсинга страниц сайта важно ограничивать, так как не все сайты могут выдержать большого количества проверок/обращений в секунду. Потому в настройках configuration — speed надо поставить отметку напротив Limit URS/s и выбрать количество обращений в секунду. Установите показатель на 10. После начала парсинга обратите внимание на то, как сайт справляется с таким количеством обращений и при надобности уменьшите его.
Чтобы ваш IP не заблокировали при парсинге используйте proxy-сервер. Для этого просто поставьте отметку в меню proxy configuration напротив user proxy.
Поиск списка страниц можно настроить по данным, которые содержаться либо не содержаться на страницах. Для этого вводим нужные нам параметры в Custom Filter Configuration.
Далее все установленные настройки необходимо сохранить. Желательно сделать их настройками по умолчанию, чтобы не настраивать заново каждый раз.
Internal
Поиск и исправление пустых страниц
Во вкладке Internal мы можем провести анализ всех страниц сайта и понять, какие из них нужно наполнить контентом, а какие необходимо будет закрыть от индексации. Чтобы найти такие страницы надо настроить фильтр на html и экспортировать список в Exel. В полученном файле сортируем список по возрастанию показателя Word Count. Для удобства можно перенести эту колонку ближе к списку ссылок на страницы. Нам надо отфильтровать страницы с ответом сервера 200, это можно сделать в колонке Status Code (исключаем 301 и 302). В результате вверху списка мы увидим страницы, на которых значительно меньше контента, чем на других. Зачастую это такие страницы авторизации, корзина и т.п. Их можно исключить из индексации. Для этого надо добавить инструкцию disallow для каждой такой страницы в файл robots.txt.
Далее собираем в отдельный список страницы, на которых нет контента. В результате получим страницы двух видов — отсутствующий товар и отсутствующий текст. Следовательно, их надо либо заполнить, либо закрыть.
Анализ перелинковки
Такой анализ покажет количество входящих и исходящих ссылок страниц и уровень их вложенности. Самые важные страницы должны иметь меньше исходящих ссылок и больше входящих, а также быть максимально приближенными к главной странице.
Чтобы отсортировать страницы по уровню вложенности фильтруем Level или проверяем какую-то страницу, вписав её url в поиск.
Чтобы проверить количество входящих ссылок сортируем колонку inlinks по убыванию. Соответственно, вверху списка будет страница, получающая самое большое количество ссылок с других страниц. Также нужно убедиться что с важных страниц нет перелинковки на неважные, такие как страницы, предназначенные для регистрации, авторизации, корзина товаров и т.п.
External
Поиск и исправление внешних ссылок
Очень важно периодически перепроверять сайт и просматривать на какие ресурсы с него идут ссылки. Может быть такое, что веб-мастер поставит на вашем сайте ссылку на свой ресурс, или вовсе сайт взломают и поставят невидимые ссылки. Крайне важно контролировать все исходящие ссылки с сайта.
Чтобы определить с каких страниц вашего сайта ссылка ведёт на конкретную внешнюю страницу выберете ссылку на неё в списке и во вкладке In Links увидите список страниц, ссылающихся на неё.
Также вы можете выгрузить (Bulk Export) всю информацию о внешних ссылках (All Out Links) — с какой страницы на какую — на вашем сайте.
Response Codes
В этой вкладке вы можете посмотреть какой ответ сервер даёт на все внутренние и внешние ссылки. В идеале все ответы должны быть 200, но на практике у вас всегда будут и ошибки и редиректы.
Для того чтобы найти страницы, на которые сервер отвечает ошибкой выбираем во вкладке Response Codes фильтр Client Error (4xx). Список страниц, с которых идут ссылки на битые страницы можно посмотреть внизу в In Links или же выполнит выгрузку Bulk Export — Client Error (4xx) in links. Все ссылки с ошибками надо исправить.
Для того чтобы найти редиректы выбираем фильтр Redirects (3xx). Удобнее будет выгрузить список в файл Exel. В полученном отчёте вы найдёте список страниц, с которых идёт редирект (Adress) и на которые он приводит (Redirect URL). Если выполнить выгрузку Bulk Export — Redirect (3xx) in links, то получим список страниц, с которых (Source) и по которым (Destination) происходит редирект. Теперь нужно сделать так, чтобы страницы из второго отчёта (Source) вели на правильные страницы из первого отчёта (Redirect URL).
Если на некоторые страницы сервер не отвечает, то есть ответ — No Response, то, скорее всего, причиной этому послужила большая нагрузка на сайт, созданная программой, или блокировка вашего IP. В этом случае для дальнейшей проверки понадобится сменить IP, либо же использовать proxy. Также необходимо уменьшить скорость проверки, чтобы не перегрузить сайт снова.
URL

Ошибки, связанные с URL ищем при помощи таких фильтров, как Non ASCII Characters, Underscores, Duplicate, Dynamic, Over 115 characters.
Non ASCII Characters покажет вам ссылки, в структуре которых есть символы, не входящие в кодировку ASCII. Такие ссылкии нужно исправить, чтобы избежать проблем с ними в будущем.
Underscores покажет ссылки, в которых используется символ нижнего подчёркивания. Вместо него лучше использовать дефис, но это не критично.
Duplicate как понятно из называния покажет дубликаты страниц.
Dynamic выведет список ссылок, в которых содержатся параметры (&,? и т.п.).
Over 115 characters покажет список URL длина которых превышает 115 символов. Не нужно проставлять слишком много ключевиков в ссылке, так как это даст поисковику сигнал о том, что на сайте может быть переспам.
Page Title
В этой вкладке вы можете просмотреть полную информацию о мета-тегах.
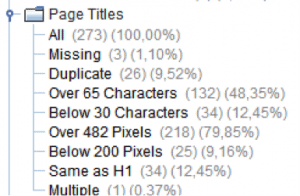
Выбрав фильтр Missing, вы увидите страницы, на которых отсутствует title и сможете его прописать.
Фильтр Multiple поможет вам увидеть страницы, на которых мета-тег title использовался более одного раза. Такую ошибку допускают редко, но лучше проверить.
Если title дублируется, то наверняка на сайте продублирована целая страница. Выясняем причину появления дубликата и устраняем её.
Фильтр Same as H1 укажет вам на страницы сайта, на которых совпадает H1 и title. Такие совпадения нежелательны, потому исправьте title на страницах из полученного списка.
После исправления всех этих ошибок можно приступить к оптимизации title.
В идеале title не должен превышать 65 символов, но и не должен быть меньше 30 символов. Если title не соответствует данным параметрам — исправьте его.
Description
В этой вкладке расписана подробная информация по мета тегу description. Зачастую этот мета-тег используется для формирования сниппета, который выводится в поисковике. Лучше заполнить description вручную, чем ставить на автоматическую генерацию. Анализировать его нужно так же как и title.
Keywords
В этой вкладке вы увидите полную информацию по тегу keywords. Тем не менее этот тег уже практически не используется. Но если вы его заполняете, то убедитесь что его содержание уникально.
Н1
Этот тег не так важен для поисковой оптимизации, как другие вышеперечисленные, но все же прописать его лучше правильно. Тут вы сможете увидеть на каких страницах этот тег отсутствует (Missing), на каких дублируется (Duplicate), на каких превышает рекомендованный размер (Over 70 characters) и на каких повторяется (Multiply).
Н2
Тут вы увидите информацию такого же рода, как по Н1, только для Н2. Для вас важно отследить чтобы тег был использован правильно, так как часто при вёрстке его проставляют там, где можно было использовать <div> или стили. В таком случае h2 будет дублироваться.
Images
В этой вкладке вы можете проследить за тем, были ли допущены ошибки при использовании картинок. Если изображения имеют слишком большой размер (Over 100kb), не имеют описания alt (Missing Alt Text) или же имеют слишком длинное описание (Alt Text Over 100 Characters).
Directives
В этой вкладке вы можете проверить правильность использования директив, таких как rel=»canonical», rel=»prev» и rel=»next».
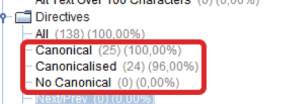
Например, проверим правильно ли используется директива rel=»canonical». Для этого выбираем фильтры Canonical, Canonicalised, No Canonical. Далее просматриваем страницы с директивой rel=»canonical». Смотрим чтобы каноническая ссылка вела на релевантную страницу с ответом сервера 200. Следим чтобы не было повторного использования директивы. Следим чтобы канонические ссылки не вели на главную страницу.
Чтобы обнаружить неправильное использование этой директивы заходим в отчёты (Reports) и выбираем там Canonical Errors.
Анализ sitemap.xml
После завершения парсинга сайта нужно проверить список ссылок в файле sitemap.xml и проследить чтобы там не было страниц с дублирующимся контентом, несуществующих страниц или тех, по которым происходит редирект.
Далее собираются данные о страницах в этой файле и по ним проводится полная проверка, по всем указанным выше пунктам. В особенности внимательно проверяем Response Codes — ответ сервера должен быть 200 для всех страниц.
В этой статье мы как пример рассмотрели программу Screaming Frog SEO Spider. Но существуют и другие программы для аудита сайта. Главное — проверить сайт тщательно по всем пунктам, чтобы максимально оптимизировать его техническую сторону под поисковую систему.